

04.08.2020
Neo4j, the leader in graph technology, announced the availability of Neo4j for Graph Data Science, the first data science environment built to harness the predictive power of relationships for enterprise deployments.
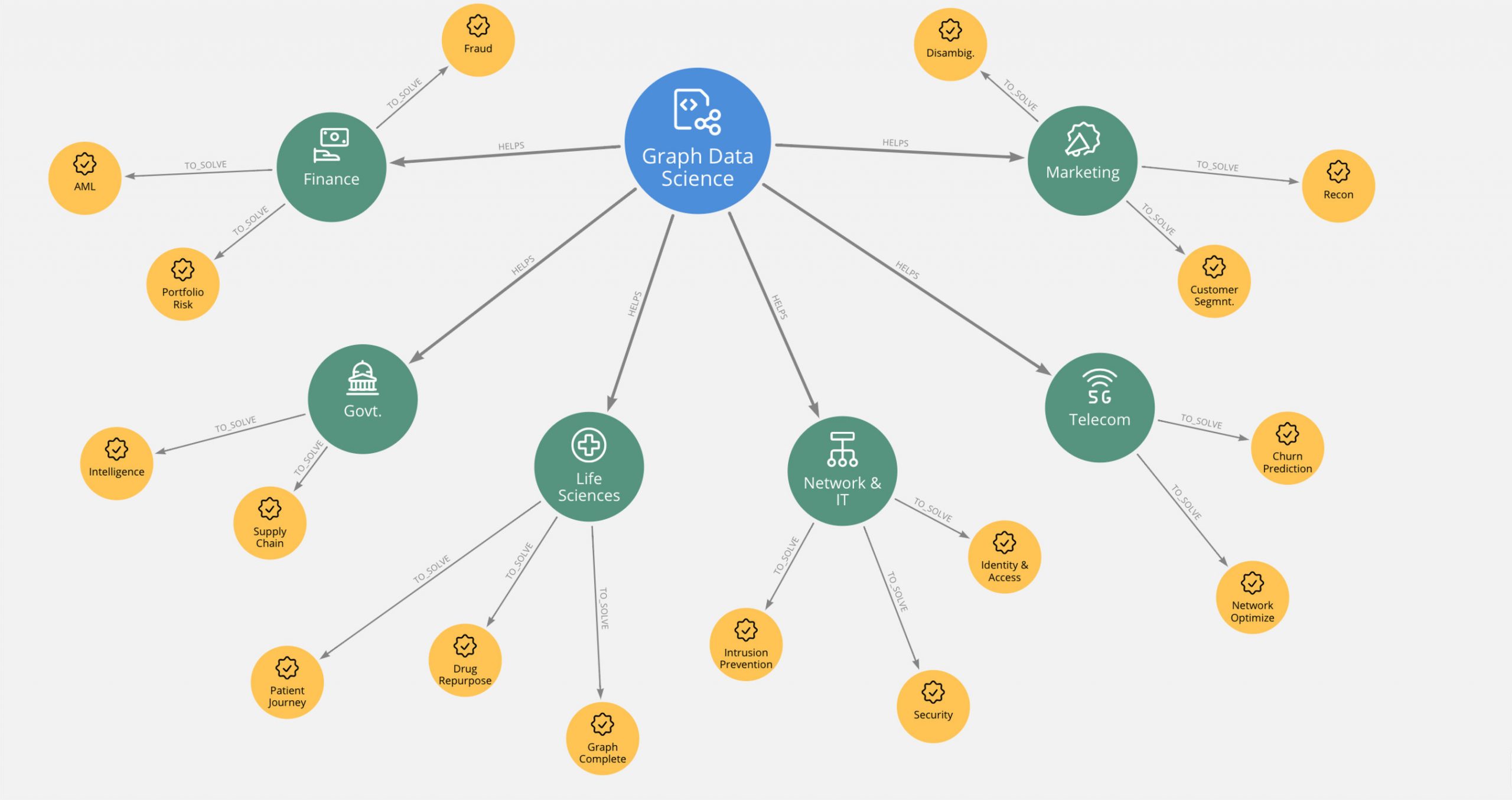
The unpredictability of the current economic climate underscores the need for organizations to get more value out of existing datasets, continually improve predictive accuracy and meet rapidly changing business requirements. Neo4j for Graph Data Science helps data scientists leverage highly predictive, yet largely underutilized relationships and network structures to answer unwieldy problems. Examples include user disambiguation across multiple platforms and contact points, identifying early interventions for complicated patient journeys and predicting fraud through sequences of seemingly innocuous behavior.
Neo4j for Graph Data Science combines a native graph analytics workspace and graph database with scalable graph algorithms and graph visualization for a reliable, easy-to-use experience. This framework enables data scientists to confidently operationalize better analytics and machine learning models that infer behavior based on connected data and network structures.
Alicia Frame, Lead Product Manager and Data Scientist at Neo4j, explained why Neo4j for Graph Data Science is the most expeditious way to generate better predictions.
“A common misconception in data science is that more data increases accuracy and reduces false positives,” explained Frame. “In reality, many data science models overlook the most predictive elements within data – the connections and structures that lie within. Neo4j for Graph Data Science was conceived for this purpose – to improve the predictive accuracy of machine learning, or answer previously unanswerable analytics questions, using the relationships inherent within existing data.”
Take fraud analysis, such as detecting identity fraud and fraud rings, as an example that spans areas from financial services and insurance to the government sector and tax evasion. Even the smallest predictive improvement translates into millions of dollars of savings. Neo4j for Graph Data Science makes it easier to make those incremental improvements without altering existing machine learning pipelines. Below are some simple steps illustrating how Neo4j for Graph Data Science fits into a fraud prediction workflow:
A data scientist can reveal suspicious groups of transactions using community detection algorithms, like Connected Components, to analyze behavior.
They can then dive deeper by applying graph algorithms such as Betweenness Centrality or PageRank to uncover hidden structures such as accounts with unusual influence over the flow of money or information.
An analyst could explore these clusters in an intuitive way and collaborate with fraud experts using Neo4j Bloom to infer which elements (i.e., features) are most likely predictive of criminal behavior.
They can perform “what if” analyses or even chain “recipes” of graph algorithms together with a mutable in-memory workspace where their graphs are reshaped on-the-fly.
Once the algorithmic recipes have been validated and understood, they can be used for machine learning models that are operationalized to proactively prevent – and not merely detect – fraud.
Neo4j for Graph Data Science enables data scientists to answer questions that are only addressable through understanding relationships and data structures. Graph algorithms are a subset of data science tools that capitalize on network structure to infer meaning and make predictions such as:
Cluster and neighbor identification through community detection and similarity algorithms
Influencer identification through centrality algorithms
Topological pattern matching through pathfinding and link prediction algorithms
With Neo4j for Graph Data Science, teams confidently deploy a proven solution at massive scale to run optimized graph algorithms over tens of billions of nodes with production features such as deterministic seeding, which provides starter values and consistent results for reproducible machine learning workflows. Through intelligent integration of network analytics and a database, Neo4j automates data transformations so users get maximum compute performance for analytics and native graph storage for persistence.
Ben Squire, Senior Data Scientist at Meredith Corporation, a leading media and marketing services company with publications reaching 190 million unduplicated American consumers every month, including nearly 95 percent of U.S. women, across broadcast television, print, digital, mobile, voice and video, shared his experience with Neo4j for Graph Data Science.
“Providing relevant content to online users, even those who don’t authenticate, is essential to our business,” said Squire. “We use the graph algorithms in Neo4j to transform billions of page views into millions of pseudonymous identifiers with rich browsing profiles. Instead of ‘advertising in the dark’, we now better understand our customers which translates into significant revenue gains and better-served consumers.”
Dr. Alexander Jarasch, the Head of Data and Knowledge Management at the German Center for Diabetes Research (DZD) and collaborator on COVIDgraph.org, explained how Neo4j for Graph Data Science offers an intuitive data science experience with logical parameters and Neo4j Bloom for comprehensive graph exploration.
“Nothing is more pressing today than understanding COVID-19,” said Jarasch. “Graphs give us the ability to bring together the salient information around this confounding disease and provide a synthesized view across heterogeneous data. Today’s understanding of this coronavirus is severely hampered by minimal peer-reviewed research and the absence of long-term clinical trials. Neo4j for Graph Data Science will help us to identify where we need to direct biomedical research, resources, and efforts.”
http://neoj4.com
Comments are closed.